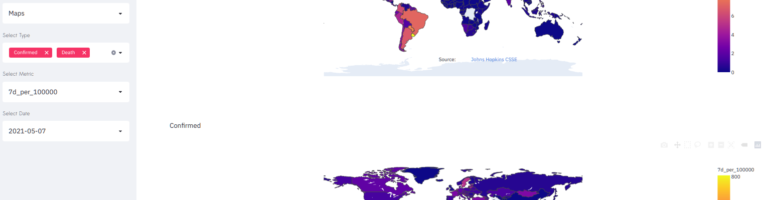
New version of Covid19 dashboard
Update from May 19, 2023: The dashboard is now disabled as of today. Corona is officially over. Numbers are no longer collected (see the screenshot of the dashboard before it was disabled). Everyone is tired of Corona and simply wants to move on. However – up to now – Corona …