
Intro:
Knime is a very powerful machine learning tool, particularly suitable for the management of complicated workflows as well as rapid prototyping.
It has recently become yet more useful with the arrival of easy-to-use Python nodes. This is true because sometimes the set of nodes – which is large – still may not provide the exact functionality that you need. On the other hand, Python is flexible enough to do anything easily. Therefore the marriage of the two is very powerful.
This post is about the transfer of the three previous time series prediction posts into a knime workflow.
This will provide for a good overview of the dataflow, making it thus more easily manageable.
The workflow code is available on github:
Assumptions:
We assume and that the set-up as already been done by the user, we specify Anaconda as our Python installation.
With the installation completed, transferring a Python script, even if it uses special packages, is then very easy.
In fact the entire script can be put into one Python node. This is however not very useful. The main purpose of knime to have nodes that are reusable, much like LEGO pieces.
In the series we had a 2-dimensional setup of factors: what type of data, and the prediction model. This needs to be reflected in the nodes. Therefore we’ll use python nodes reflecting the model specification, the data specification. Aditionally we’ll dedicade nodes to the configuration and plotting. In fact we’ll use a set of so-called Python-script nodes and Python-edit-variable nodes for this purpose.
Why Python-edit-variable nodes?
Knime has a flow_variables structure which can be used to pass around an unlimited number of string type variables. We will make extensive use of data serialisation to take advantage of this.
There is a Python package called json_tricks, which allows you to do this very easily, in particular it can be used to pass around entire class instances.
Python edit variable are ideal for this purpose as they highlight the fact that the flow_variables are changed in the node.
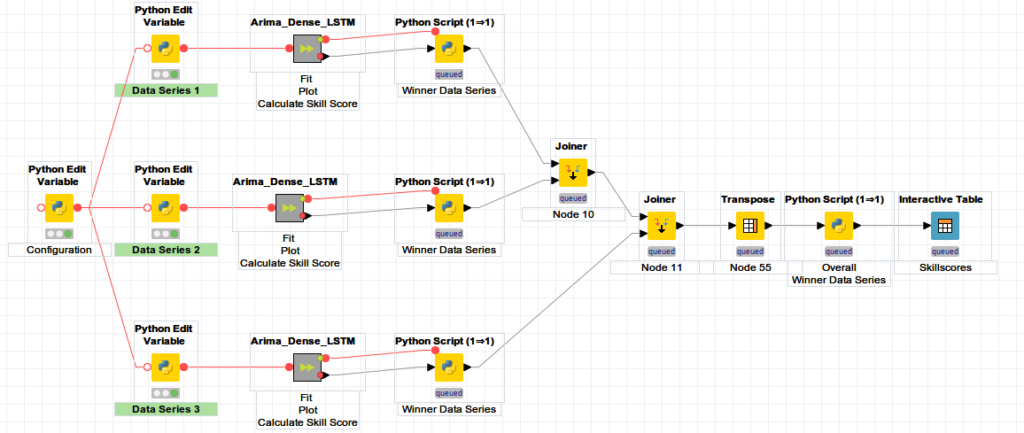
The workflow contains inter alia
- Python script nodes
- Python Edit Variable nodes
- Joiner nodes
- Transpose Nodes
We also use metanodes. These are a way of organising a set of nodes into one node to make the entire workflow more readable.
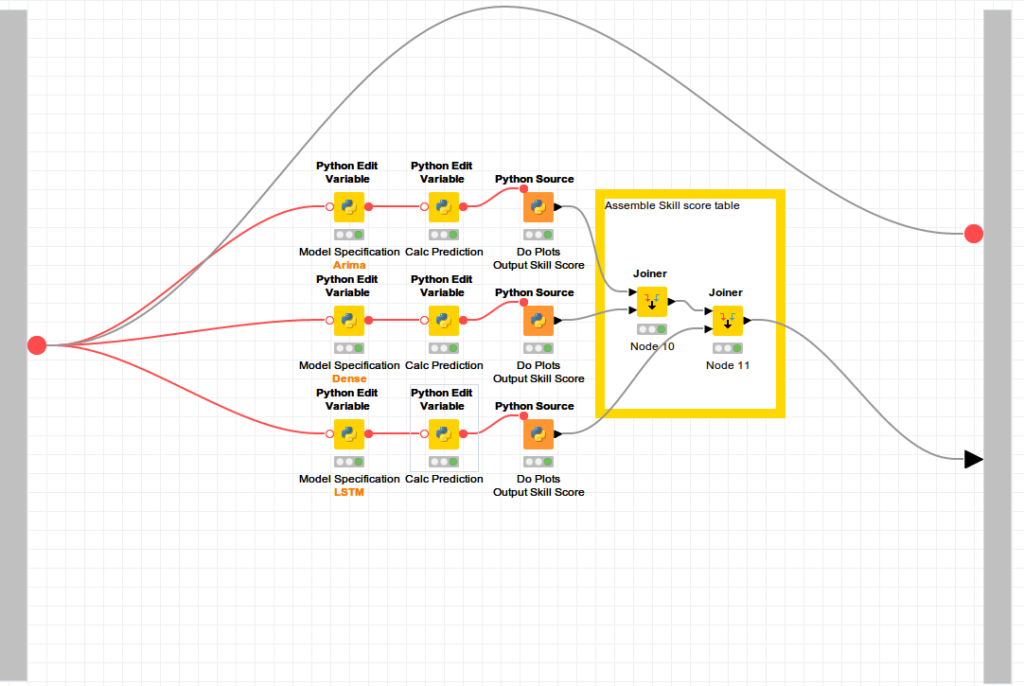
Tips and tricks
- Using the flow_variables is a way of overcoming the constrained inputs and outputs of the Python based nodes.
- This we use in combination with a package to serialise arbitrary objects, json tricks.
- For the interior of the metanode will used curved connections for enhanced readability.
Conclusion
Knime is an advanced tool for rapid prototyping, which recently has gained the explicit power of Python. One can safely say that it has never been easier to transfer Python code to knime.
We have demonstrated the passing of arbitrary objects between knime nodes via serialisation. This is the basis for using Python based nodes as LEGO like building blocks.