
Update 3 June 2021: I have updated the code and notebook in github, to reflect the most recent api version of the packages, especially pytorch-lightning.
The years 2018-2020 have been the start of a new era in the field of natural language processing (nlp). This means that today computers can understand humans much better. Something similar occurred in image processing about six years earlier, when computers learned to understand images much better. The recent development in natural language processing (nlp) has been compared favourably to that of image processing, by many authors.
In this post we’ll demonstrate code that uses the vastly improved natural language processing (nlp) software landscape. In particular we use it for one of the classic nlp use cases: Text classification.
More specifically, we use the new capabilities to predict from a user’s app review in the Google Play Store the star rating that the same user gave to the app.. This is useful e.g. for spotting clearly erroneous star ratings, e.g. where the user misinterpreted the rating scale thinking: “5 is very bad, 1 is very good”, whereas the normal meaning is : “5 is very good, 1 is very bad”.1
Paradigm Shift
The dawn of the new era witnessed a true paradigm shift. The new paradigm shift is dominated by one thing: fine tuning. This mirrors again the earlier development in images, when a similar paradigm shift occurred. So you could ask: What is this fine tuning? Really, it is quite simple. Fine tuning is jargon for reusing a general model trained on a huge amount of general data for the specific data at hand. The model trained on such general data is called “pretrained”. So for instance a model might typically have been pretrained on Wikipedia, e.g. Wikipedia English, which means that it would have learned and therefore now “understands” general English. If our specific task then is to classify newspaper articles, it will typically be useful to do a moderate amount of fine tuning on the newspaper data, so that the model better understands the specificity of newspaper English.
In this article we will demonstrate some code that follows this new paradigm. In particular we will demonstrate this finetuning on a Google App Rating dataset.
For the better organisation of our code and general convenience, we will us pytorch lightning.
The paradigm shift in 2018-2020 was driven by the arrival of many new models. A timeline of these arrivals is shown in figure Timeline.
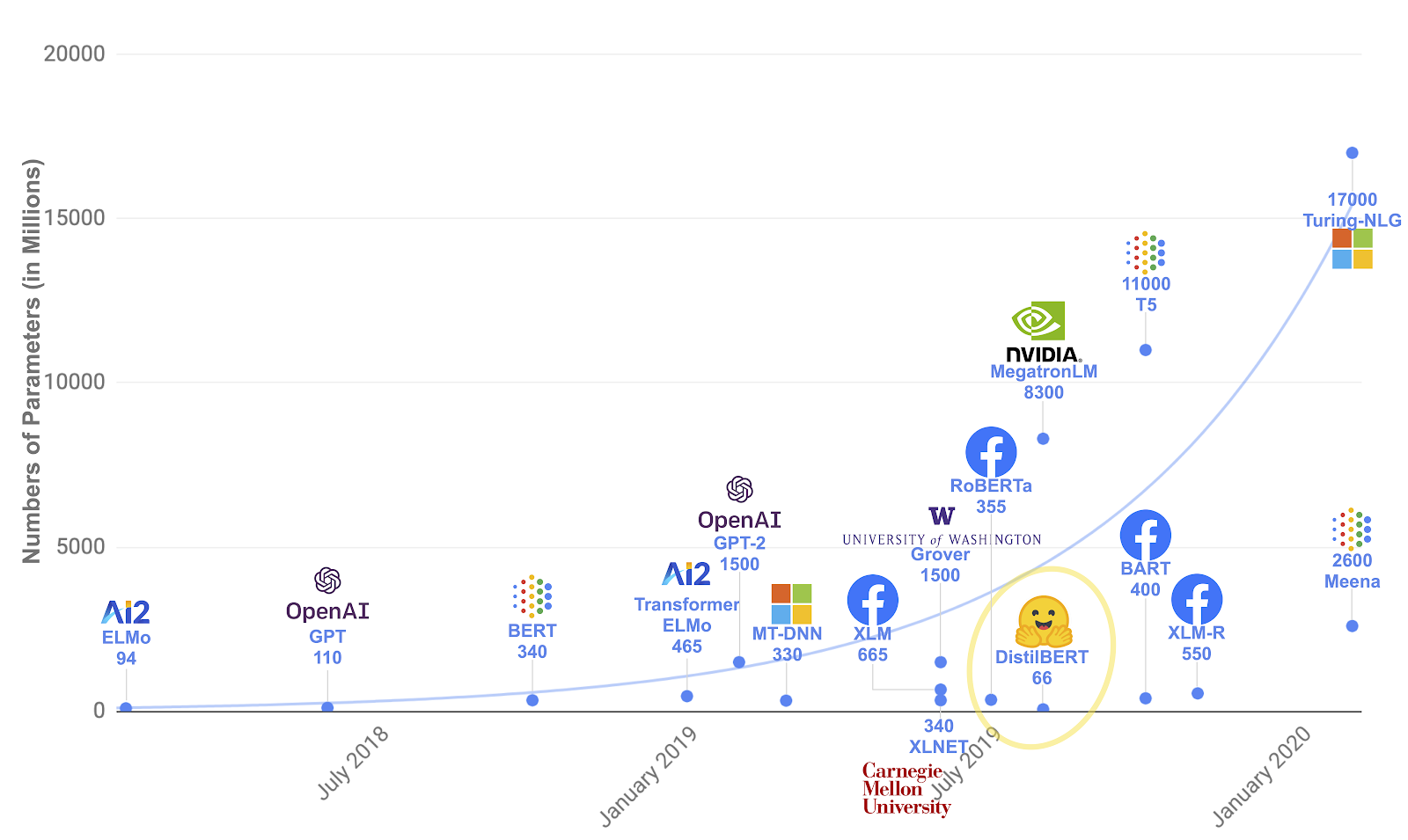
In the diagram you can clearly see that the models have generally been getting bigger. They also generally get better, as this is of course quite a general trend in research, otherwise things would not be worth publishing. The en vogue expression for a proof that a model is indeed an improvement is “beating the state of the art” or “beating SOTA”. The state of the art is measured for various text related tasks, simpler ones such as text classification, and more complicated ones such as text summarisation.
So the progress of the state of the art is partially driven by model size. The model size is generally by the number of free parameters that need to be trained, a number that is typically measured in millions. In fact a new model that was published in May 2020, the very trendy so-called GPT-33 by OpenAI, has 175 000 million parameters, which is more than 10 times more than the largest model shown in the diagram, Turing-NLG with 17 000 million parameters. Turing-NLG had previously been the biggest model.
To some extent this is a worrying trend, which reinforces the lead of the very big players in the field. In fact OpenAI – in a significant deviation from current practices – has not published a pre-trained version of the GPT-3 model, but rather prefers to sell an API service which is powered by the model. On the other hand, there are very few players who can afford the cost to train the model, e.g. the hardware cost plus electricity bill would be quite large. One estimate puts the price tag at ~5 million US Dollars4, which is certainly out of the question for most individual researchers.
Another thing to notice in the diagram is the continual and steady flow of new models. So there is really no single point of the revolution. This is quite a general observation5 and it can be seen very plainly e.g. in the evolution of playing strength of history’s strongest6 chess playing software stockfish7.
The code provided here in the present post allows you to switch models very easily.
Possible choices for pretrained models are
- albert-base-v2
- bert-base-uncased
- distilbert-base-uncased
We have run the colab notebook with these choices, other pretrained models from huggingface might also be possible.
The interest in these models can be expressed like this:
- BERT8 (published in October 2018 by researchers from Google) managed to capture a lot of attention. The enormous hold on the nlp researchers collective psyche is illustrated by the choice of subsequent model names incorporating the term BERT, such as roBERTa9, ALBERT10, distilBERT2. Therefore BERT is to many researchers and practitioners a symbol of the nlp revolution and is as suitable as any model in being a representative of the paradigm shift.
- DistilBERT2 (published in October 2019 by researchers from Huggingface) was put forward with the explicit aim of going against the prevailing big-is-beautiful trend, by creating a BERT like model that is “Smaller, Faster, Cheaper and Lighter“2.
- ALBERT10 (version 1 was published in September 2019 by researchers from Google and Toyota, an updated version 2 was published in January 2020) was an effort to beat BERT and existing SOTAs while limiting model size.
The bigger-is-better trend has since continued unabated, so by now BERT itself at 340 million parameters or ~1.3 Gigabyte looks small in comparison to recent models, however, our preference is for a model that can be fine-tuned using the limited resources that are available to an individual. Therefore in the notebook we show results for DistilBERT.
To run the different model, e.g. the BERT Model, just one name needs to be changed in the Colab notebook, namely for bert-base-uncased the python command should be changed to
%%time
! python distil_bert_fine_tuning_lightning_google \
--pretrained bert-base-uncased \
--gpus 1 \
--auto_select_gpus true \
--nr_frozen_epochs 5where distilbert-base-uncased was changed to bert-base-uncased. For albert-base-v2 the same procedure can be used.
We have also run the code for BERT instead of distilBERT, and the results are only marginally better. For ALBERT they were marginally worse. However, this post here will not provide a detailed comparison of model performance.
We will do the fine-tuning with Google Colab, which is currently arguably the best GPU resource that is entirely free.
Requirements
- Hardware
- A computer with at least 4 GB Ram
- Software
- The computer can run on Linux, MacOS or Windows
- VS code is an advantage
- Wetware
- Familiarity with Python
- For the technical code, a familiarity with pytorch lightning definitely helps
- … as does a familiarity with nlp transformers
- … as does a familiarity in particular with hugginface/transformers
For the technical code of this post we owe thanks to the following two posts, they also contain some background information, just in the case the reader wants to brush up on any of the wetware requirements.
- Chris McCormick and Nick Ryan : ps://mccormickml.com/2019/07/22/BERT-fine-tuning. In fact Chris McCormick and Nick Ryan have done a fantastic job and they have also produced a very good video series covering BERT, called the BERT Research Series.
- Venelin Valkov: https://www.curiousily.com/posts/sentiment-analysis-with-bert-and-hugging-face-using-pytorch-and-python and the accompanying notebook : https://colab.research.google.com/drive/1PHv-IRLPCtv7oTcIGbsgZHqrB5LPvB7S. Venelin’s posts are also highly instructive, e.g. he shows how to build a classifier just by using the Bert language model (“BertModel”) and combining with some layers, instead of using the purpose-built Sentiment Classifier (“BertForSequenceClassification”).
The defining features of our post where our post distinguishes itself from Chris and Nick’s and/or Venelin’s are:
- Task : We focus on the classic task of text classification, using a different dataset, viz. Google Play app reviews dataset from Venelin Valkov’s post. Similar to Venelin, different from Chris.
- Colab: We train with Google Colab, which, as mentioned, is currently arguably the best GPU resource that is entirely free. It’s use is greatly simplified by point Structure. Similar to Venelin, similar to Chris. The main difference here is, that we develop locally first, e.g. in VS code, and then “wrap” the code with a Colab notebook.
- Structure: We structure our code with Pytorch Lightning, which makes everything very readable. Further it makes switching from coding locally with your cpu, to running it on a cloud-based gpu very simple (a “breeze”), literally one line of code. Different from Venelin, different from Chris.
Transformers from Huggingface
The github hosted package https://github.com/huggingface/transformers is the go-to-place when it comes to modern natural language processing. Its popularity can be seen from its fast rising github stars, currently at Star . The package supplies the architecture of a huge zoo of models such as BERT, roBERTa, ALBERT and distilBERT. It is available in pytorch and tensorflow.
But best of all it provides fully pretrained models. With the notable exception of GPT 3 🙁.
Structure with Pytorch Lightning
The github hosted package https://github.com/PytorchLightning/pytorch-lightning also is a highly popular package.
Its popularity can also be seen from its equally fast rising github stars, currently at Star .
This is from the lightning README:
“Lightning disentangles PyTorch code to decouple the science from the engineering by organizing it into 4 categories:
- Research code (the LightningModule).
- Engineering code (you delete, and is handled by the Trainer).
- Non-essential research code (logging, etc… this goes in Callbacks).
- Data (use PyTorch Dataloaders or organize them into a LightningDataModule).
Once you do this, you can train on multiple-GPUs, TPUs, CPUs and even in 16-bit precision without changing your code!”
So, in essence, it promotes readability, reasonable expectations regarding code structure, the promise you can focus on the interesting bits, while being able to switch painlessly from cpu to gpu/tpu.
Code
The code is available on github https://github.com/hfwittmann/transformer_finetuning_lightning.
As mentioned, for the technical code, it is helpful to have a familiarity with
- pytorch lightning definitely
- nlp transformers
- hugging face transformers
Workflow
We start with a python file which we can develop locally in eg VS Code, thereby benefitting from its convenience features, above all the very nice debugging facilities. Because of the ease of switching from CPU to GPU code facilitated by pytorch-lightning, we can do this on our local CPU.
Once this is done, we transfer the file to Google Drive, mount the appropriate folder in Google Colab, and then execute our file from a jupyter-type Colab notebook.
To make it really useful we use the excellent argparse facilities of pytorch-lightning, so that we can eg. change various parameters via the command line on the fly.
So here’s the fully commented python code:
## Start : Import the packages
import pandas as pd
import os
import pathlib
import zipfile
import wget
import gdown
import torch
from torch import nn
from torch import functional as F
from torch.utils.data import TensorDataset
from torch.utils.data import random_split
from torch.utils.data import RandomSampler
from torch.utils.data import DataLoader
from transformers import AutoTokenizer
from transformers import AutoModelForSequenceClassification
from transformers import AutoConfig
from transformers import AdamW
from transformers import get_linear_schedule_with_warmup
import pytorch_lightning as pl
from pytorch_lightning.callbacks import EarlyStopping
# End : Import the packages
# %%
# Remark: pl.LightningModule is derived from torch.nn.Module It has additional methods that are part of the
# lightning interface and that need to be defined by the user. Having these additional methods is very useful
# for several reasons:
# 1. Reasonable Expectations: Once you know the pytorch-lightning-system you more easily read other people's
# code, because it is always structured in the same way
# 2. Less Boilerplate: The additional class methods make pl.LightningModule more powerful than the nn.Module
# from plain pytorch. This means you have to write less of the repetitive boilerplate code
# 3. Perfact for the development lifecycle Pytorch Lightning makes it very easy to switch from cpu to gpu/tpu.
# Further it supplies method to quickly run your code on a fraction of the data, which is very useful in
# the development process, especially for debugging
class Model(pl.LightningModule):
def __init__(self, *args, **kwargs):
super().__init__()
self.save_hyperparameters()
# a very useful feature of pytorch lightning which leads to the named variables that are passed in
# being available as self.hparams.<variable_name> We use this when refering to eg
# self.hparams.learning_rate
# freeze
self._frozen = False
# eg https://github.com/stefan-it/turkish-bert/issues/5
config = AutoConfig.from_pretrained(self.hparams.pretrained,
num_labels=5,
output_attentions=False,
output_hidden_states=False)
print(config)
A = AutoModelForSequenceClassification
self.model = A.from_pretrained(self.hparams.pretrained, config=config)
print('Model Type', type(self.model))
# Possible choices for pretrained are:
# distilbert-base-uncased
# bert-base-uncased
# The BERT paper says: "[The] pre-trained BERT model can be fine-tuned with just one additional output
# layer to create state-of-the-art models for a wide range of tasks, such as question answering and
# language inference, without substantial task-specific architecture modifications."
#
# Huggingface/transformers provides access to such pretrained model versions, some of which have been
# published by various community members.
#
# BertForSequenceClassification is one of those pretrained models, which is loaded automatically by
# AutoModelForSequenceClassification because it corresponds to the pretrained weights of
# "bert-base-uncased".
#
# Huggingface says about BertForSequenceClassification: Bert Model transformer with a sequence
# classification/regression head on top (a linear layer on top of the pooled output) e.g. for GLUE
# tasks."
# This part is easy we instantiate the pretrained model (checkpoint)
# But it's also incredibly important, e.g. by using "bert-base-uncased, we determine, that that model
# does not distinguish between lower and upper case. This might have a significant impact on model
# performance!!!
def forward(self, batch):
# there are some choices, as to how you can define the input to the forward function I prefer it this
# way, where the batch contains the input_ids, the input_put_mask and sometimes the labels (for
# training)
b_input_ids = batch[0]
b_input_mask = batch[1]
has_labels = len(batch) > 2
b_labels = batch[2] if has_labels else None
# there are labels in the batch, this indicates: training for the BertForSequenceClassification model:
# it means that the model returns tuple, where the first element is the training loss and the second
# element is the logits
if has_labels:
loss, logits = self.model(b_input_ids,
attention_mask=b_input_mask,
labels=b_labels)
# there are labels in the batch, this indicates: prediction for the BertForSequenceClassification
# model: it means that the model returns simply the logits
if not has_labels:
loss, logits = None, self.model(b_input_ids,
attention_mask=b_input_mask,
labels=b_labels)
return loss, logits
def training_step(self, batch, batch_nb):
# the training step is a (virtual) method,specified in the interface, that the pl.LightningModule
# class stipulates you to overwrite. This we do here, by virtue of this definition
loss, logits = self(
batch
) # self refers to the model, which in turn acceses the forward method
tensorboard_logs = {'train_loss': loss}
# pytorch lightning allows you to use various logging facilities, eg tensorboard with tensorboard we
# can track and easily visualise the progress of training. In this case
return {'loss': loss, 'log': tensorboard_logs}
# the training_step method expects a dictionary, which should at least contain the loss
def validation_step(self, batch, batch_nb):
# the training step is a (virtual) method,specified in the interface, that the pl.LightningModule
# class wants you to overwrite, in case you want to do validation. This we do here, by virtue of this
# definition.
loss, logits = self(batch)
# self refers to the model, which in turn accesses the forward method
# Apart from the validation loss, we also want to track validation accuracy to get an idea, what the
# model training has achieved "in real terms".
labels = batch[2]
predictions = torch.argmax(logits, dim=1)
accuracy = (labels == predictions).float().mean()
return {'val_loss': loss, 'accuracy': accuracy}
# the validation_step method expects a dictionary, which should at least contain the val_loss
def validation_epoch_end(self, validation_step_outputs):
# OPTIONAL The second parameter in the validation_epoch_end - we named it validation_step_outputs -
# contains the outputs of the validation_step, collected for all the batches over the entire epoch.
# We use it to track progress of the entire epoch, by calculating averages
avg_loss = torch.stack([x['val_loss']
for x in validation_step_outputs]).mean()
avg_accuracy = torch.stack(
[x['accuracy'] for x in validation_step_outputs]).mean()
tensorboard_logs = {'val_loss': avg_loss, 'val_accuracy': avg_accuracy}
return {
'val_loss': avg_loss,
'log': tensorboard_logs,
'progress_bar': {
'avg_loss': avg_loss,
'avg_accuracy': avg_accuracy
}
}
# The training_step method expects a dictionary, which should at least contain the val_loss. We also
# use it to include the log - with the tensorboard logs. Further we define some values that are
# displayed in the tqdm-based progress bar.
def configure_optimizers(self):
# The configure_optimizers is a (virtual) method, specified in the interface, that the
# pl.LightningModule class wants you to overwrite.
# In this case we define that some parameters are optimized in a different way than others. In
# particular we single out parameters that have 'bias', 'LayerNorm.weight' in their names. For those
# we do not use an optimization technique called weight decay.
no_decay = ['bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [{
'params': [
p for n, p in self.named_parameters()
if not any(nd in n for nd in no_decay)
],
'weight_decay':
0.01
}, {
'params': [
p for n, p in self.named_parameters()
if any(nd in n for nd in no_decay)
],
'weight_decay':
0.0
}]
optimizer = AdamW(optimizer_grouped_parameters,
lr=self.hparams.learning_rate,
eps=1e-8
# args.adam_epsilon - default is 1e-8.
)
# We also use a scheduler that is supplied by transformers.
scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=0,
# Default value in run_glue.py
num_training_steps=self.hparams.num_training_steps)
return [optimizer], [scheduler]
def freeze(self) -> None:
# freeze all layers, except the final classifier layers
for name, param in self.model.named_parameters():
if 'classifier' not in name: # classifier layer
param.requires_grad = False
self._frozen = True
def unfreeze(self) -> None:
if self._frozen:
for name, param in self.model.named_parameters():
if 'classifier' not in name: # classifier layer
param.requires_grad = True
self._frozen = False
def on_epoch_start(self):
"""pytorch lightning hook"""
if self.current_epoch < self.hparams.nr_frozen_epochs:
self.freeze()
if self.current_epoch >= self.hparams.nr_frozen_epochs:
self.unfreeze()
class Data(pl.LightningDataModule):
# So here we finally arrive at the definition of our data class derived from pl.LightningDataModule.
#
# In earlier versions of pytorch lightning (prior to 0.9) the methods here were part of the model class
# derived from pl.LightningModule. For better flexibility and readability the Data and Model related parts
# were split out into two different classes:
#
# pl.LightningDataModule and pl.LightningModule
#
# with the Model related part remaining in pl.LightningModule
#
# This is explained in more detail in this video: https://www.youtube.com/watch?v=L---MBeSXFw
def __init__(self, *args, **kwargs):
super().__init__()
# self.save_hyperparameters()
if isinstance(args, tuple): args = args[0]
self.hparams = args
# cf this open issue: https://github.com/PyTorchLightning/pytorch-lightning/issues/3232
print('args:', args)
print('kwargs:', kwargs)
# print(f'self.hparams.pretrained:{self.hparams.pretrained}')
print('Loading BERT tokenizer')
print(f'PRETRAINED:{self.hparams.pretrained}')
A = AutoTokenizer
self.tokenizer = A.from_pretrained(self.hparams.pretrained)
print('Type tokenizer:', type(self.tokenizer))
# This part is easy we instantiate the tokenizer
# So this is easy, but it's also incredibly important, e.g. in this by using "bert-base-uncased", we
# determine, that before any text is analysed its all turned into lower case. This might have a
# significant impact on model performance!!!
#
# BertTokenizer is the tokenizer, which is loaded automatically by AutoTokenizer because it was used
# to train the model weights of "bert-base-uncased".
def prepare_data(self):
# Even if you have a complicated setup, where you train on a cluster of multiple GPUs, prepare_data is
# only run once on the cluster.
# Typically - as done here - prepare_data just performs the time-consuming step of downloading the
# data.
print('Setting up dataset')
prefix = 'https://drive.google.com/uc?id='
id_apps = "1S6qMioqPJjyBLpLVz4gmRTnJHnjitnuV"
id_reviews = "1zdmewp7ayS4js4VtrJEHzAheSW-5NBZv"
pathlib.Path('./data').mkdir(parents=True, exist_ok=True)
# Download the file (if we haven't already)
if not os.path.exists('./data/apps.csv'):
gdown.download(url=prefix + id_apps,
output='./data/apps.csv',
quiet=False)
# Download the file (if we haven't already)
if not os.path.exists('./data/reviews.csv'):
gdown.download(url=prefix + id_reviews,
output='./data/reviews.csv',
quiet=False)
def setup(self, stage=None):
# Even if you have a complicated setup, where you train on a cluster of multiple GPUs, setup is run
# once on every gpu of the cluster.
# typically - as done here - setup
# - reads the previously downloaded data
# - does some preprocessing such as tokenization
# - splits out the dataset into training and validation datasets
# Load the dataset into a pandas dataframe.
df = pd.read_csv("./data/reviews.csv", delimiter=',', header=0)
if self.hparams.frac < 1:
df = df.sample(frac=self.hparams.frac, random_state=0)
df['score'] -= 1
# Report the number of sentences.
print('Number of training sentences: {:,}\n'.format(df.shape[0]))
# Get the lists of sentences and their labels.
sentences = df.content.values
labels = df.score.values
t = self.tokenizer(
sentences.tolist(), # Sentence to encode.
add_special_tokens=True, # Add '[CLS]' and '[SEP]'
max_length=128, # Pad & truncate all sentences.
padding='max_length',
truncation=True,
return_attention_mask=True, # Construct attn. masks.
return_tensors='pt' # Return pytorch tensors.
)
# Convert the lists into tensors.
input_ids = t['input_ids']
attention_mask = t['attention_mask']
labels = torch.tensor(labels)
# Print sentence 0, now as a list of IDs. print('Example') print('Original: ', sentences[0])
# print('Token IDs', input_ids[0]) print('End: Example')
# Combine the training inputs into a TensorDataset.
dataset = TensorDataset(input_ids, attention_mask, labels)
# Create a 90-10 train-validation split.
# Calculate the number of samples to include in each set.
train_size = int(self.hparams.training_portion * len(dataset))
val_size = len(dataset) - train_size
print('{:>5,} training samples'.format(train_size))
print('{:>5,} validation samples'.format(val_size))
self.train_dataset, self.val_dataset = random_split(
dataset, [train_size, val_size],
generator=torch.Generator().manual_seed(42))
def train_dataloader(self):
# as explained above, train_dataloader was previously part of the model class derived from
# pl.LightningModule train_dataloader needs to return the a Dataloader with the train_dataset
return DataLoader(
self.train_dataset, # The training samples.
sampler=RandomSampler(
self.train_dataset), # Select batches randomly
batch_size=self.hparams.batch_size # Trains with this batch size.
)
def val_dataloader(self):
# as explained above, train_dataloader was previously part of the model class derived from
# pl.LightningModule train_dataloader needs to return the a Dataloader with the val_dataset
return DataLoader(
self.val_dataset, # The training samples.
sampler=RandomSampler(self.val_dataset), # Select batches randomly
batch_size=self.hparams.batch_size, # Trains with this batch size.
shuffle=False)
# %%
if __name__ == "__main__":
# Two key aspects:
# - pytorch lightning can add arguments to the parser automatically
# - you can manually add your own specific arguments.
# - there is a little more code than seems necessary, because of a particular argument the scheduler
# needs. There is currently an open issue on this complication
# https://github.com/PyTorchLightning/pytorch-lightning/issues/1038
import argparse
from argparse import ArgumentParser
parser = ArgumentParser()
# We use the parts of very convenient Auto functions from huggingface. This way we can easily switch
# between models and tokenizers, just by giving a different name of the pretrained model.
#
# BertForSequenceClassification is one of those pretrained models, which is loaded automatically by
# AutoModelForSequenceClassification because it corresponds to the pretrained weights of
# "bert-base-uncased".
# Similarly BertTokenizer is one of those tokenizers, which is loaded automatically by AutoTokenizer
# because it is the necessary tokenizer for the pretrained weights of "bert-base-uncased".
parser.add_argument('--pretrained', type=str, default="bert-base-uncased")
parser.add_argument('--nr_frozen_epochs', type=int, default=5)
parser.add_argument('--training_portion', type=float, default=0.9)
parser.add_argument('--batch_size', type=float, default=32)
parser.add_argument('--learning_rate', type=float, default=2e-5)
parser.add_argument('--frac', type=float, default=1)
# parser = Model.add_model_specific_args(parser) parser = Data.add_model_specific_args(parser)
parser = pl.Trainer.add_argparse_args(parser)
args = parser.parse_args()
# TODO start: remove this later
# args.limit_train_batches = 10 # TODO remove this later
# args.limit_val_batches = 5 # TODO remove this later
# args.frac = 0.01 # TODO remove this later
# TODO end: remove this later
# start : get training steps
d = Data(args)
d.prepare_data()
d.setup()
args.num_training_steps = len(d.train_dataloader()) * args.max_epochs
# end : get training steps
dict_args = vars(args)
m = Model(**dict_args)
args.early_stop_callback = EarlyStopping('val_loss')
trainer = pl.Trainer.from_argparse_args(args)
# fit the data
trainer.fit(m, d)
# %%
[nbconvert url=”https://github.com/hfwittmann/transformer_finetuning_lightning/blob/master/nlp-fine-tune-run.ipynb”]
References
- 1.Aralikatte R, Sridhara G, Gantayat N, Mani S. Fault in Your Stars: An Analysis of Android App Reviews. Vol abs/1708.04968.; 2017. http://arxiv.org/abs/1708.04968
- 2.Sanh V, Debut L, Chaumond J, Wolf T. DistilBERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter. arxiv; 2019. https://arxiv.org/abs/1910.01108
- 3.B. Brown T, Mann B, Ryder N, et al. Language Models Are Few-Shot Learners.; 2020. https://arxiv.org/abs/2005.14165
- 4.Dickson B. The untold story of GPT-3 is the transformation of OpenAI. https://bdtechtalks.com/. Published September 12, 2020. Accessed September 12, 2020. https://bdtechtalks.com/2020/08/17/openai-gpt-3-commercial-ai/#:~:text=According%20to%20one%20estimate%2C%20training,increase%20the%20cost%20several%2Dfold.
- 5.Ridley M. How Innovation Works: And Why It Flourishes in Freedom. Harper (May 19, 2020); 2020.
- 6.. CCRL 40/15 Rating List. CCRL 40/15 Rating List. Published September 12, 2020. Accessed September 12, 2020. “CCRL 40/15”. computerchess.org.uk
- 7.Pohl S. Stockfish testing. Stefan Pohl Computer Chess. Published September 12, 2020. Accessed September 12, 2020. https://www.sp-cc.de/
- 8.Devlin J, Chang M-W, Lee K, Toutanova K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. Vol abs/1810.04805.; 2018. http://arxiv.org/abs/1810.04805
- 9.Liu Y, Ott M, Goyal N, et al. RoBERTa: A Robustly Optimized BERT Pretraining Approach. Published online 2019.
- 10.Lan Z, Chen M, Goodman S, Gimpel K, Sharma P, Soricut R. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. Published online 2019. https://arxiv.org/abs/1909.11942